

2021 年二月底,遊戲公司 Cygames 終於把醞釀了三年的巨作《ウマ娘 プリティーダービー》從褲襠裡掏了出來,遊戲一上市就以迅雷不及掩耳之勢佔據了各平台的熱門第一,並在約 20 天後下載數就達到了 300 萬,更是在遊戲推出第五天營收就高達 20 億日圓,風靡全日本及海外宅圈。
《ウマ娘 プリティーダービー(下略稱ウマ娘)》為一款養成類型遊戲,玩家可以挑選自己喜歡的馬娘進行培養,在一個周回中對她進行各種訓練、並參與賽馬比賽,最終獲得大賽決勝完成養成,養成完畢的馬娘可以參加競技場,也可以作為下一隻馬娘培養時的繼承因子。

■ 研究原因和目標
在《ウマ娘》中,培養時的「訓練選項」選擇是非常重要,有些選擇甚至足以左右你的馬娘是否能拿到大賽決勝,遊戲中野具備了一些機率變數,這對新手不太友好、甚至是老手也未必能把每一個選擇選對,
故本研究想要利用深度學習中的強化學習(Reinforcement Learning)方法,以類神經網路模型來玩《ウマ娘》,藉由深度學習來找到在某情況中應該選擇的正確選項。
■ 研究方法
本研究之程式設計分為兩部分,一是設計一套《ウマ娘》模擬器,二是深度學習訓練模型。
一、《ウマ娘》模擬器
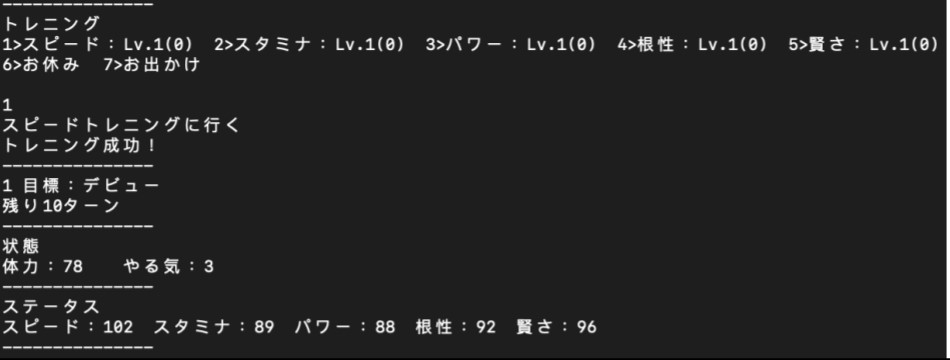
首先以 C++編寫一模仿ウマ娘的系統做出的一個執行在純文字介面(Terminal 介面)的模擬器,該模擬器會顯示數值目標,並讓玩家選擇訓練類型或休息的選項並反映在數值上,最後藉數值比對判斷玩家使否成功通關;
此模擬器中模擬了馬娘的體力(体力)、幹勁(やる気)、五種訓練項目選擇(スピード、スタミナ、パワー、根性、賢さ)、兩種休息方式選擇(お休み、お出かけ)、訓練項目等級(トレニングレベル),
一些特殊劇情、因子引繼、輔助卡(サポートカード)的系統則未實裝;遊戲方式為模擬器會輸出馬娘的五項數值、目前體力與幹勁,並讓玩家選擇 5+2 種訓練與休息方法,選擇後模擬器會依據目前所剩體力、幹勁以及訓練項目等級來判斷訓練是否成功、會增加多少數值,並將增加後的數值輸出,並重複步驟。
程式運行狀況如下圖:
機器學習部分則使用 Python 中的 Pytorch 張量處理 Package 作為框架設計類神經網路,本研究中主要利用強化學習(Reinforcement learning)中基礎的 DQN(Deep Q-Network)算法來做;
首先,強化學習為假設一 Agent 在一 Environment 中,Agent 即為我們的機器學習程式,Environment 則為ウマ娘模擬器,當 Agent 觀察 Environment 的狀態(status)做一動作(action),Environment 會返還一個新的狀態並給予一個獎勵(reward),而 Agent 的目的就是將獲得的獎勵最大化;
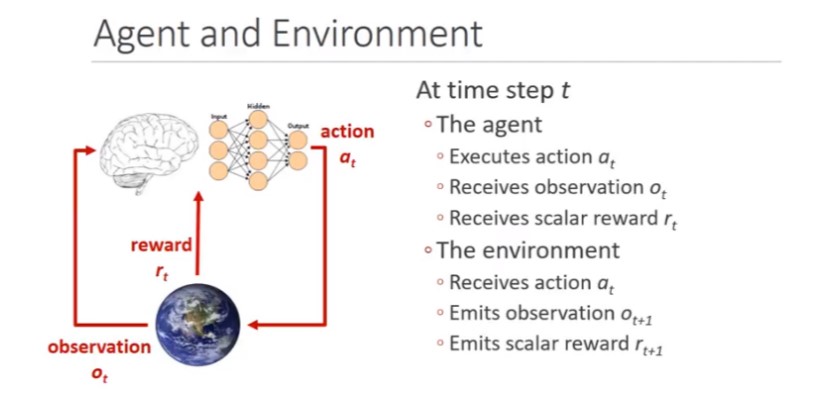
而 DQN 就是以 Q-function,一種可以計算做一動作後未來可獲得的獎勵的期望值的函式做獎勵的估算,最終目的是找到能獲得最多
獎勵的 Q-function,
由於當輸入的參數很多時 Q-function 會很難計算,於是乾脆用類神經網路來當作 Q-function,這也就是 DQN 的原理;

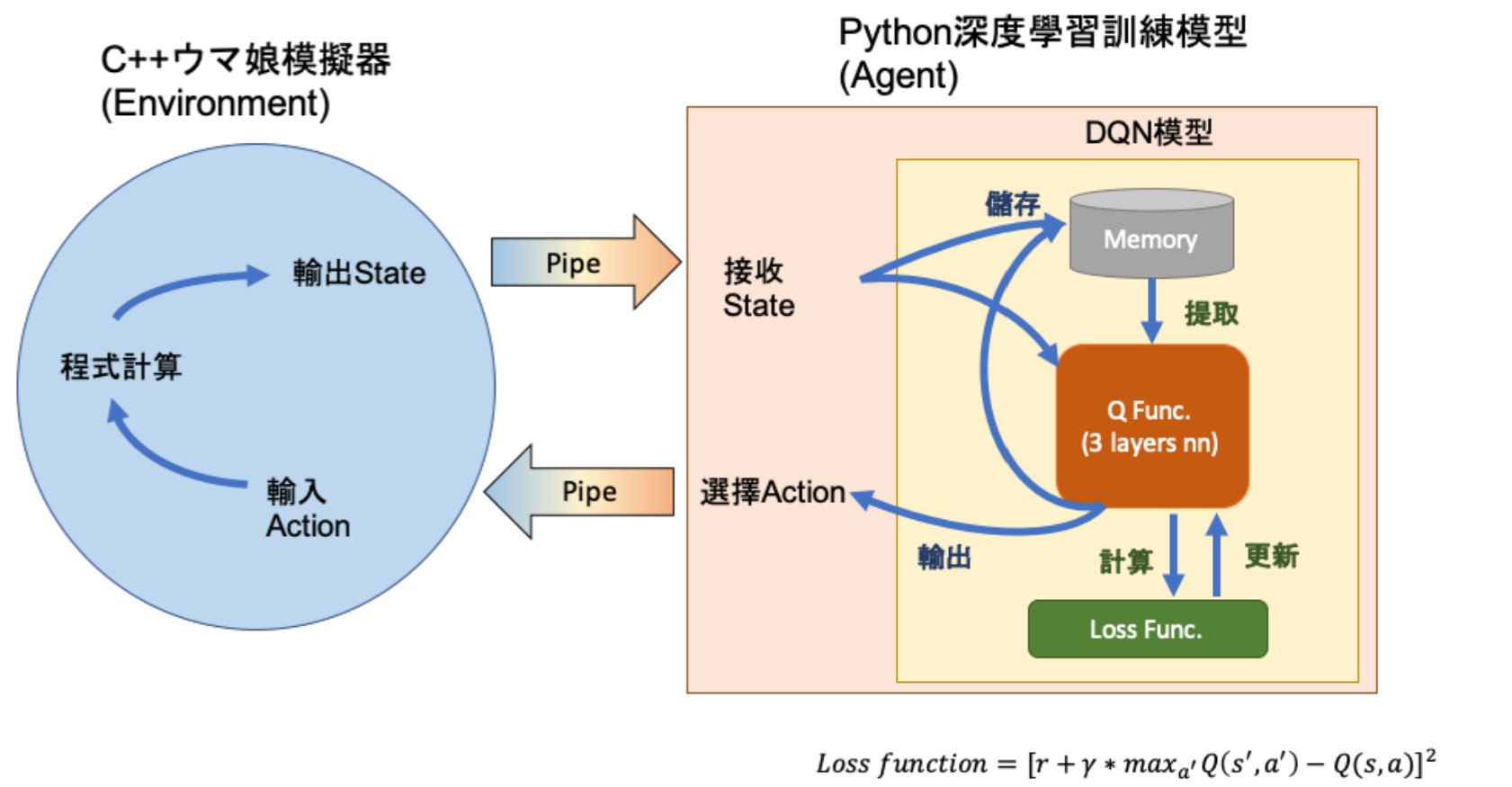
最後我們用 Subprocess 建立 IO Pipe 來將資料在兩程式間進行資料傳輸就完成全部架構。程式架構如下圖:
■ 研究過程與結果
一、DQN 模型訓練結果
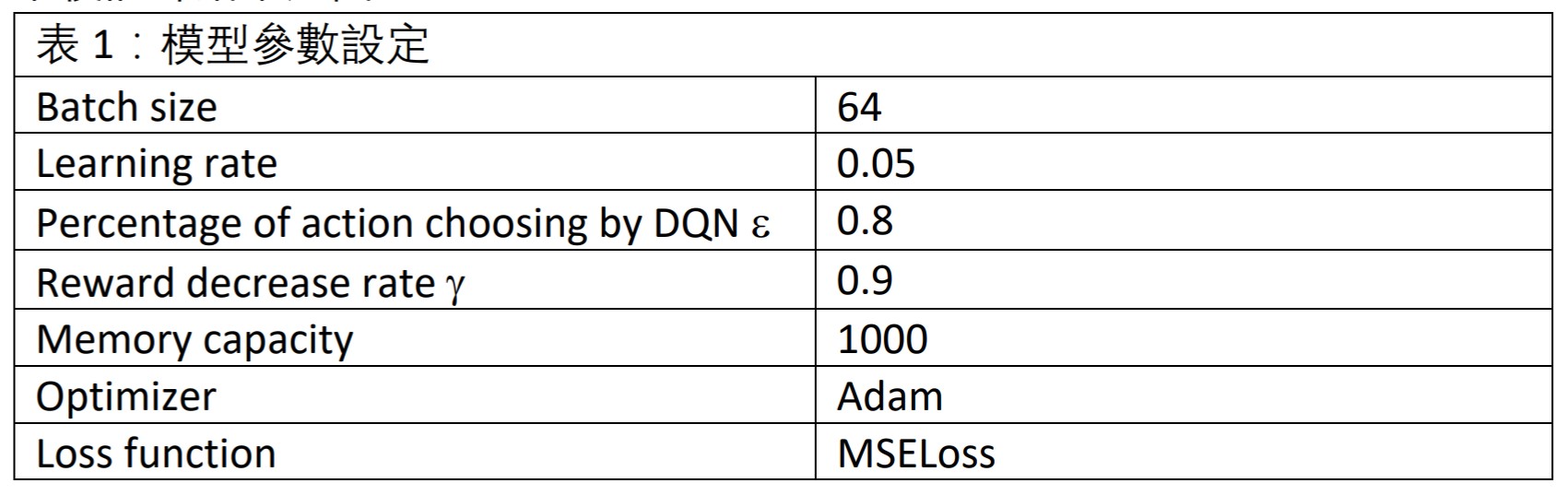
我首先設定類神經網絡為三層+輸出層,前三層的 activation function 為 ReLU,最後一層輸出層則為 Softmax;參數設定如表 1,Reward 給予方法為:「若完成一次賽事則+1,賽事失敗則-1,一般訓練失敗則-0.01」;最後訓練結果如下圖。
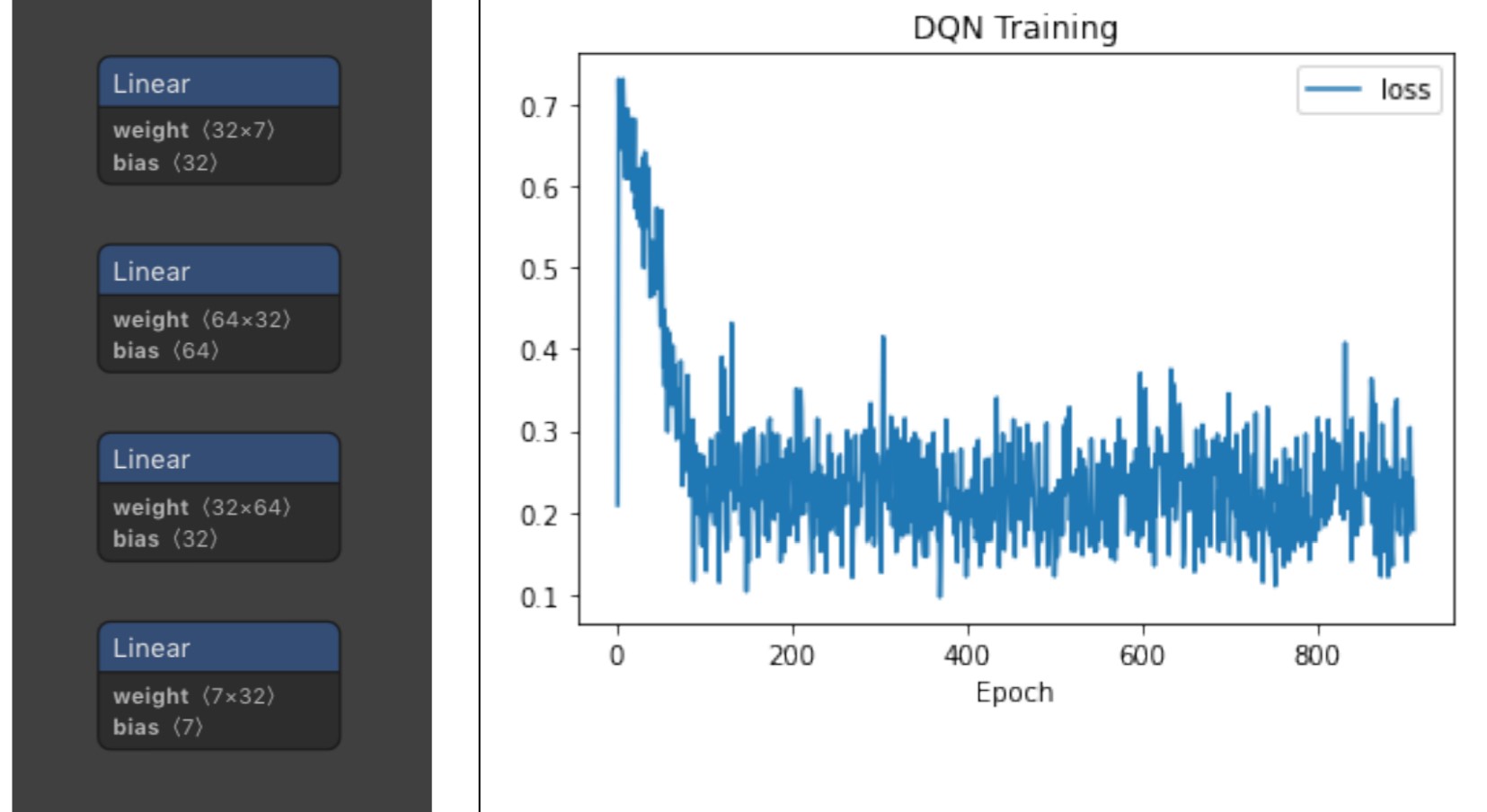
由上圖中可以看到,訓練結果不甚理想,剛開始 loss 雖有明顯的下降,但到約第 100 個 Epoch、 loss 下降到 0.2 左右後就不再下降,實際測試模型的預測結果發現模型傾向只選一個選項,且每次訓練出來的模型都不一樣,
像本次圖中的模型為全部都只選第二個選項,也就是スタミナ訓練,唯一有一些不同選擇處則是因為動作是隨機選的的,由於在表 1 中的 e 是設為 0.8,所以有 20%的機率的動作選擇會是隨機的,除此之外不管數值如何變化,模型都會選擇固定選項,
由此可知模型並未學習到我們希望他學習的如沒有體力時要休息回體力等技巧,另外也有嘗試減少層數、改變 Learning rate、改變 Batch size…等等,但結果都相差無幾,由於 loss 圖形根本一樣,就不放上來了,本次實驗也算宣告失敗。
■ 小結
目前強化學習的算法開發還未到穩定階段,網路上查詢到的論文也多是在遊玩上世紀 70, 80 年代的 Atari games,其遊戲變數與《賽馬娘》有很大的落差。如果 Environment status 與行動的關係度小可能就無法訓練,故本研究僅為期末作業一試作之項目,有可能在模型設計上還不純熟、設計不夠周延導致導致失敗;
未來應該會繼續嘗試其他進階算法如 DDQN 等,嘗試讓模型能學到如何遊玩《ウマ娘》。
■ 說明
作者|陳柏翰 材料系 24 級
本文是我們於國立大學之課程討論作業的成果之一。讓學生選擇自己有興趣的題目,透過遊玩遊戲或觀看動畫,進而提出問題,加以解釋與觀察,最後成為期末作業。
提供學生作為觀看者、參與者與評論者的一種練習與嘗試,也與我們推廣的「輕學術」有相連結之處。我們希望透過這種方式,讓學生遊玩觀賞自己喜歡的作品,進而獲得練習的機會。所以雖然本《賽馬娘》的研究成果算是失敗,但仍公開給大家看,作為有意義之遊玩和學習過程。
SOURCE
(1) https://medium.com/雞雞與兔兔的工程世界/機器學習-ml-notereinforcement-learning-強化學習-dqn-實作 atari-game-7f9185f833b0
(2) https://japanese.engadget.com/app-game-cygames-113230964.html
(3) https://hackmd.io/@shaoeChen/Bywb8YLKS/https%3A%2F%2Fhackmd.io%2F%4
0shaoeChen%2FSyez2AmFr
(4) https://towardsdatascience.com/double-deep-q-networks-905dd8325412
(5) https://zhuanlan.zhihu.com/p/337553995
(6) arXiv:1509.06461v3 [cs.LG] (https://arxiv.org/abs/1509.06461)





